
Hello friends
I've problem with my Centos 4.3. On start some information: 1. serwer HP DL 380 x Intel(R) Xeon(TM) CPU 3.40GHz 2. RAM 4GB 3. HDD storage FC 4. kernel 2.6.9-34.0.2.ELsmp #1 SMP
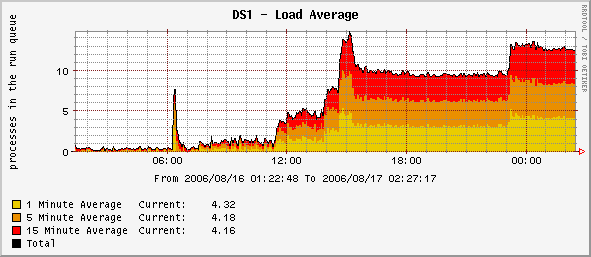
This serwer is working with another one (that some configuration) in RHEL cluster (locking by DLM), as a file serwer with samba-3.0.22. Samba have about 100 simultaneus sessions. Problem is with load of my system. It's growing up. I disabled/enabled samba processes, disabled backup system, disabled antyvirus for samba, but this didn't help. CPU utilization is 5-10%, ram utilization ~2GB. I don't have any idea what's wrong. Any suggestion?
Regards Marek
Sorry for my english
{kind=link}

Do you have any cron jobs starting around 23:00 and 07:00 ?? or anything on another machine starting at those times ?
If you reboot does it drop back down ? or does it keep climbing ?
Ian
On 17/08/06, Marek Dabrowski marek.dabrowski@infor.pl wrote:
Hello friends
I've problem with my Centos 4.3. On start some information:
- serwer HP DL 380 x Intel(R) Xeon(TM) CPU 3.40GHz
- RAM 4GB
- HDD storage FC
- kernel 2.6.9-34.0.2.ELsmp #1 SMP
This serwer is working with another one (that some configuration) in RHEL cluster (locking by DLM), as a file serwer with samba-3.0.22. Samba have about 100 simultaneus sessions. Problem is with load of my system. It's growing up. I disabled/enabled samba processes, disabled backup system, disabled antyvirus for samba, but this didn't help. CPU utilization is 5-10%, ram utilization ~2GB. I don't have any idea what's wrong. Any suggestion?
Regards Marek
Sorry for my english
CentOS mailing list CentOS@centos.org http://lists.centos.org/mailman/listinfo/centos
Ian Harper napisał(a):
Do you have any cron jobs starting around 23:00 and 07:00 ?? or anything on another machine starting at those times ?
No I havn't got any task in cron. I checkced it't.
If you reboot does it drop back down ? or does it keep climbing ?
After restart everything is all right. Load is about < 1.
Ian
On 17/08/06, *Marek Dabrowski* <marek.dabrowski@infor.pl mailto:marek.dabrowski@infor.pl> wrote:
Hello friends I've problem with my Centos 4.3. On start some information: 1. serwer HP DL 380 x Intel(R) Xeon(TM) CPU 3.40GHz 2. RAM 4GB 3. HDD storage FC 4. kernel 2.6.9-34.0.2.ELsmp #1 SMP This serwer is working with another one (that some configuration) in RHEL cluster (locking by DLM), as a file serwer with samba-3.0.22. Samba have about 100 simultaneus sessions. Problem is with load of my system. It's growing up. I disabled/enabled samba processes, disabled backup system, disabled antyvirus for samba, but this didn't help. CPU utilization is 5-10%, ram utilization ~2GB. I don't have any idea what's wrong. Any suggestion? Regards Marek Sorry for my english
{kind=link}

This serwer is working with another one (that some configuration) in RHEL cluster (locking by DLM), as a file serwer with samba-3.0.22. Samba have about 100 simultaneus sessions. Problem is with load of my system. It's growing up. I disabled/enabled samba processes, disabled backup system, disabled antyvirus for samba, but this didn't help. CPU utilization is 5-10%, ram utilization ~2GB. I don't have any idea what's wrong. Any suggestion?
Does this problem only happen on one server, but not the other, or does it happen on both servers?
Barry Brimer napisał(a):
This serwer is working with another one (that some configuration) in RHEL cluster (locking by DLM), as a file serwer with samba-3.0.22. Samba have about 100 simultaneus sessions. Problem is with load of my system. It's growing up. I disabled/enabled samba processes, disabled backup system, disabled antyvirus for samba, but this didn't help. CPU utilization is 5-10%, ram utilization ~2GB. I don't have any idea what's wrong. Any suggestion?
Does this problem only happen on one server, but not the other, or does it happen on both servers? _______________________________________________ CentOS mailing list CentOS@centos.org http://lists.centos.org/mailman/listinfo/centos
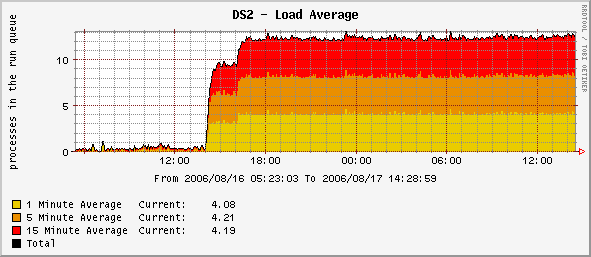
I thing that problem is on both, but second one is working like print serwer, and load don't jump.
Regards
{kind=link}

Marek Dabrowski wrote:
Barry Brimer napisał(a):
This serwer is working with another one (that some configuration) in RHEL cluster (locking by DLM), as a file serwer with samba-3.0.22. Samba have about 100 simultaneus sessions. Problem is with load of my system. It's growing up. I disabled/enabled samba processes, disabled backup system, disabled antyvirus for samba, but this didn't help. CPU utilization is 5-10%, ram utilization ~2GB. I don't have any idea what's wrong. Any suggestion?
Does this problem only happen on one server, but not the other, or does it happen on both servers?
I thing that problem is on both, but second one is working like print serwer, and load don't jump.
Okay, I'm having a disconnect here. None of these graphs make sense to me. The system load as stated in the legend on the graphs is composed of 1, 5, and 15 minute averages. Under steady load conditions, these averages should converge. The graphs don't show that, although the numbers listed do. The graph seems to be showing the additive value of all three load averages which is bogus (or at least misleading).

Might be off track, but I personally get the impression there's a bug in the load calculation. I posted on this list a few months back where one of our boxes had a permanent load of one which started at 4am the same time as some crons kicked off. No processes were outstanding, checked for rootkits etc. Killed all processed and it stilled stayed at one with nothing running, with cpu at zero etc. Ended up rebooting and its been fine since.
On 8/17/06, Linus Hicks lihicks@gpi.com wrote:
Marek Dabrowski wrote:
Barry Brimer napisał(a):
This serwer is working with another one (that some configuration) in RHEL cluster (locking by DLM), as a file serwer with samba-3.0.22. Samba have about 100 simultaneus sessions. Problem is with load of my system. It's growing up. I disabled/enabled samba processes, disabled backup system, disabled antyvirus for samba, but this didn't help. CPU utilization is 5-10%, ram utilization ~2GB. I don't have any idea what's wrong. Any suggestion?
Does this problem only happen on one server, but not the other, or does it happen on both servers?
I thing that problem is on both, but second one is working like print serwer, and load don't jump.
Okay, I'm having a disconnect here. None of these graphs make sense to me. The system load as stated in the legend on the graphs is composed of 1, 5, and 15 minute averages. Under steady load conditions, these averages should converge. The graphs don't show that, although the numbers listed do. The graph seems to be showing the additive value of all three load averages which is bogus (or at least misleading). _______________________________________________ CentOS mailing list CentOS@centos.org http://lists.centos.org/mailman/listinfo/centos

On Thu, 2006-08-17 at 09:18 -0400, Linus Hicks wrote:
Okay, I'm having a disconnect here. None of these graphs make sense to me. The system load as stated in the legend on the graphs is composed of 1, 5, and 15 minute averages. Under steady load conditions, these averages should converge. The graphs don't show that, although the numbers listed do. The graph seems to be showing the additive value of all three load averages which is bogus (or at least misleading).
What graphing tool are you using? If you have the sysstat package installed, 'sar -A' will give you ten-minute snapshots of the values among lots of other things that might help you understand what is happening.
Les Mikesell napisał(a):
On Thu, 2006-08-17 at 09:18 -0400, Linus Hicks wrote:
Okay, I'm having a disconnect here. None of these graphs make sense to me. The system load as stated in the legend on the graphs is composed of 1, 5, and 15 minute averages. Under steady load conditions, these averages should converge. The graphs don't show that, although the numbers listed do. The graph seems to be showing the additive value of all three load averages which is bogus (or at least misleading).
What graphing tool are you using? If you have the sysstat package installed,
isag - it is in crontab
'sar -A' will give you ten-minute snapshots of the values among lots of other things that might help you understand what is happening.
I changed default perid gathering stats to 1 min.
Marek Dabrowski napisał(a):
Hello friends
I've problem with my Centos 4.3. On start some information:
- serwer HP DL 380 x Intel(R) Xeon(TM) CPU 3.40GHz
- RAM 4GB
- HDD storage FC
- kernel 2.6.9-34.0.2.ELsmp #1 SMP
This serwer is working with another one (that some configuration) in RHEL cluster (locking by DLM), as a file serwer with samba-3.0.22. Samba have about 100 simultaneus sessions. Problem is with load of my system. It's growing up. I disabled/enabled samba processes, disabled backup system, disabled antyvirus for samba, but this didn't help. CPU utilization is 5-10%, ram utilization ~2GB. I don't have any idea what's wrong. Any suggestion?
Regards Marek
Sorry for my english
I found probabyl reason of my problems... Two minutes ago I rebooted second node. Load on first node decresed from 10 to 2.01. Rebooted node have load 0.29 now. But question "why" that is happening is still open.
Regards
Marek Dabrowski napisał(a):
Marek Dabrowski napisał(a):
Hello friends
I've problem with my Centos 4.3. On start some information:
- serwer HP DL 380 x Intel(R) Xeon(TM) CPU 3.40GHz
- RAM 4GB
- HDD storage FC
- kernel 2.6.9-34.0.2.ELsmp #1 SMP
This serwer is working with another one (that some configuration) in RHEL cluster (locking by DLM), as a file serwer with samba-3.0.22. Samba have about 100 simultaneus sessions. Problem is with load of my system. It's growing up. I disabled/enabled samba processes, disabled backup system, disabled antyvirus for samba, but this didn't help. CPU utilization is 5-10%, ram utilization ~2GB. I don't have any idea what's wrong. Any suggestion?
Regards Marek
Sorry for my english
I found probabyl reason of my problems... Two minutes ago I rebooted second node. Load on first node decresed from 10 to 2.01. Rebooted node have load 0.29 now. But question "why" that is happening is still open.
Mabey I use wrong driver for network cards? Now I use tg3. bcm5700 will be better?

On Thursday 17 August 2006 17:35, Marek Dabrowski wrote:
I found probabyl reason of my problems... Two minutes ago I rebooted second node. Load on first node decresed from 10 to 2.01. Rebooted node have load 0.29 now. But question "why" that is happening is still open.
I say it's time to bring out the big hammer.. oprofile.
rough guide: * install the following rpms: oprofile kernel-smp-devel kernel-debuginfo * opcontrol --setup --vmlinux=/path/to/vmlinux/from/debuginfo-rpm when in abnormal state: opcontrol --start ; sleep a bit ; opcontrol --shutdown opreport -l -p /lib/modules/$(uname -r)/kernel | head -n 15
That should give you the top most consumers of processor time and hopefully some clues :-)
While you're at it, run vmstat for a few seconds and study the first two columns.
/Peter (who likes big hammers, everything's a nail!!)
Regards

On Thu, 2006-08-17 at 18:00 +0200, Peter Kjellström wrote:
On Thursday 17 August 2006 17:35, Marek Dabrowski wrote:
I found probabyl reason of my problems... Two minutes ago I rebooted second node. Load on first node decresed from 10 to 2.01. Rebooted node have load 0.29 now. But question "why" that is happening is still open.
I say it's time to bring out the big hammer.. oprofile.
rough guide:
- install the following rpms: oprofile kernel-smp-devel kernel-debuginfo
- opcontrol --setup --vmlinux=/path/to/vmlinux/from/debuginfo-rpm
when in abnormal state: opcontrol --start ; sleep a bit ; opcontrol --shutdown opreport -l -p /lib/modules/$(uname -r)/kernel | head -n 15
That should give you the top most consumers of processor time and hopefully some clues :-)
While you're at it, run vmstat for a few seconds and study the first two columns.
/Peter (who likes big hammers, everything's a nail!!)
hmmmm ... the title of this message does not look good :) ... I though for sure this was some serious SPAM :)

On Thu, 2006-08-17 at 14:23 -0500, Johnny Hughes wrote:
On Thu, 2006-08-17 at 18:00 +0200, Peter Kjellström wrote:
On Thursday 17 August 2006 17:35, Marek Dabrowski wrote:
<snip>
/Peter (who likes big hammers, everything's a nail!!)
hmmmm ... the title of this message does not look good :) ... I though for sure this was some serious SPAM :)
LOL! Careful! You-know-who frowns seriously upon humor!
<snip sig stuff>
William L. Maltby napisał(a):
On Thu, 2006-08-17 at 14:23 -0500, Johnny Hughes wrote:
On Thu, 2006-08-17 at 18:00 +0200, Peter Kjellström wrote:
On Thursday 17 August 2006 17:35, Marek Dabrowski wrote:
<snip>
/Peter (who likes big hammers, everything's a nail!!)
hmmmm ... the title of this message does not look good :) ... I though for sure this was some serious SPAM :)
LOL! Careful! You-know-who frowns seriously upon humor!
:-))) I understund, but now I'm after 15h of work and my sense of humor is dying :-(
Regards :-)
Hello friends
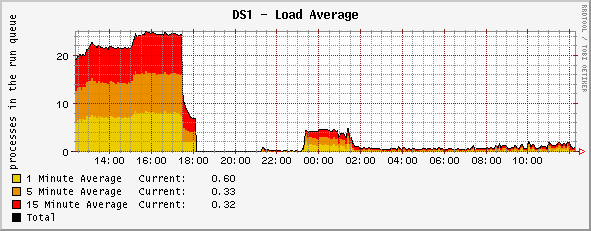
My cluster is working good!!! Now load is < ~0.3. Yesterday I changed drivers from tg3 to bcm5700 (from hp.com).
Thx all for help.
Regards Marek
{kind=link}

On 18/08/06, Marek Dabrowski marek.dabrowski@infor.pl wrote:
Hello friends
My cluster is working good!!! Now load is < ~0.3. Yesterday I changed drivers from tg3 to bcm5700 (from hp.com).
But this still remains unanswered: Why 1/5/15 minute load shows up in the graph as additions? Is the wrongtype of graph being used?
Sudev Barar napisał(a):
On 18/08/06, Marek Dabrowski marek.dabrowski@infor.pl wrote:
Hello friends
My cluster is working good!!! Now load is < ~0.3. Yesterday I changed drivers from tg3 to bcm5700 (from hp.com).
But this still remains unanswered: Why 1/5/15 minute load shows up in the graph as additions? Is the wrongtype of graph being used?
Graph is OK. It's made by cacti.
On Sat, 2006-08-19 at 02:45, Marek Dabrowski wrote:
But this still remains unanswered: Why 1/5/15 minute load shows up in the graph as additions? Is the wrongtype of graph being used?
Graph is OK. It's made by cacti.
It really doesn't make much sense to stack those values because the total is meaningless, but it does show the trend. The parts are color-coded so you can see the individual values and the one minute value is on the baseline so it is easiest to read. Just look at the one-minute part and ignore the rest.
-
 Barry Brimer
Barry Brimer -
 Ian Harper
Ian Harper -
 Ian mu
Ian mu -
 Johnny Hughes
Johnny Hughes -
 Les Mikesell
Les Mikesell -
 Linus Hicks
Linus Hicks -
 Marek Dabrowski
Marek Dabrowski -
 Peter Kjellström
Peter Kjellström -
 Sudev Barar
Sudev Barar -
 William L. Maltby
William L. Maltby